
A Brief Guide About Supervised And Unsupervised ML Models
Introduction
In day to day world of computers, you must have come across the term Machine learning or ML. Many of us are not well informed about Machine learning. But, our ignorance cannot stop ML from taking the world into its waves. So, in order to easily understand the changes in future, it would be better that we stay informed at present. Here in this article, a concise overview of Machine learning has been given.
To put it simply, we can say ML is nothing but teaching the computer to do predictions or to make decisions depending on the data available. Technically speaking it is an amalgamation of statistics and computer science. You may have come across several terms like Data Science, Artificial Intelligence, Predictive analytics, data mining and many more, all of them are sheltered under one umbrella acknowledged as Machine learning.
Machine learning can be categorized into four different divisions.
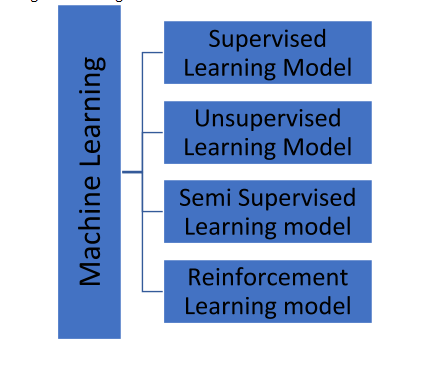
Let’s discuss the supervised and unsupervised models below in brief:
What supervised learning model is all about?
Supervised machine learning can be related to student learning in the command of a teacher. Here you provide the computer with input and output data. Both input and output data are classified for future data processing and also to provide a learning base. The idea of supervised learning came from the fact that the training dataset is teaching the algorithm similar to a teacher teaching in a class.
Here in this model, you can forecast the outcome of unforeseen data, as the algorithm has learned from output data, which is also known as labelled data. We can categorize supervised machine learning into:
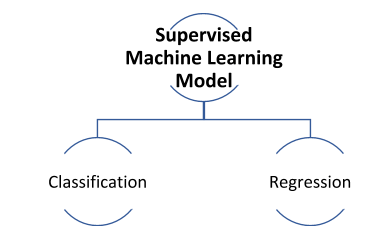
Classification: In this case, data is utilized to predict the category. For example, if you have an image it can be utilized to forecast whether it is of an animal or human.
Regression: Regression comes into the picture when you need to define the connection between two variables and also to predict how the modification in one variable is affecting the other.
What do we understand by the unsupervised machine learning model?
In this type of machine learning, you don’t have to train the computer with output data instead you have to allow the computer to work on its own to determine the information. This model particularly works with unlabeled data.
In contrast to supervised learning, using this algorithm, you can accomplish more complicated tasks.
We can categorize Unsupervised learning model into:
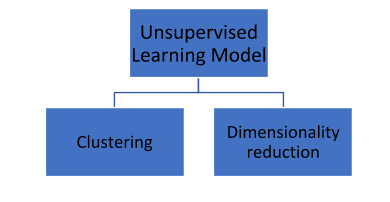
Clustering: Clustering of variables takes place according to defined criteria then further analysis is done on these clusters.
Dimensionality reduction: This is the process of reducing the dimensionality of the training data. This is due to that fact that you will find it important to remove unwanted and redundant data particularly if the input data you have given has high dimensionality.
Why we need supervised learning?
This model allows you to gather data and guess the output from the trained data. Here the trained data will support you to optimize the performance criteria. With this model, you can solve various real-world calculation problems.
What is the need for unsupervised learning?
With this model, you can discover various types of an unknown pattern of data. This will also help you to find features that can be used for categorization. Analyzation and labelling of all input data take place in presence of learner as it happens in real-time. To get a labelled data you need manual intervention whereas unlabeled data does not need that.
Now let us comprehend how supervised learning works?
In simple words, the system is provided with both input and output data to learn how they get mapped together. The target here is to provide you with a mapping function that is accurate enough to predict the output when a new algorithm is provided. To understand this, consider a real-world example that we are familiar with in our day to day life. Almost all of us use maps from google to predict the time needed to drive back to our home.
In this situation, you require to train the computer to foresee the output by generating a set of labelled data. For this, you may consider data like the weather of the day, time and day to predict the rush. These will be your input data and the time taken to drive back home will be your output data. You know if it rains it will take more time to go home but the machine does not know that you have to provide it with data and statistics.
For this example, first, we have to create a training data set that will have total travel time along with some factors like weather and time. Depending on this training dataset the machine will create a relationship between rain and travel time. And will also consider the time of the day to determine the travel time. Your labelled data will help the machine to create relationships.
How unsupervised learning works?
The algorithm here mostly works on information that has no previous training, that means here you will utilize data that is unlabeled or uncategorized.
Let us take a simple example of a baby girl and her pet dog. The baby plays with her dog every day and is familiar with it. But one fine day another dog was introduced to her whom she never met earlier. But she recognizes the feature of this new dog like four limbs, two earlobes, two eyes, etc. which is similar to her dog. This is unsupervised learning where you pick up from your previous experience.
Supervised vs Unsupervised model
Let us categorize the differences between the two models so that you can find out the differences at a glance.
| Parameters | Supervised | Unsupervised |
| Process | You have to give Input and output variables | Only input data provided |
| Input data | Algorithm is implemented with trained data | Unlabeled data is provided to the algorithm |
| Complexity | Simple | Complex |
| Data used | Trained data used to map the connection between input and output data | Output data is not provided |
| Accuracy | Trustworthy and accurate model | Accuracy is less yet trustworthy |
| Learning in real-time | Mostly offline learning takes place | Real-time learning happens |
Conclusion:
Both the models have found extensive popularity among the data scientist and analyst. As a learner, you may find it hard to choose the exact model for your application. But sometimes experienced data scientist has to test data on several models to find the best fit. Hence comprehensive knowledge of various models is necessary.
Author Bio
Great Learning is an ed-tech company that offers programs in career critical competencies such as Analytics, Data Science, Big Data, Machine Learning, Artificial Intelligence, Cloud Computing, DevOps, Digital Marketing and more.
Our programs are taken by thousands of professionals globally who build competencies in these emerging areas to secure and grow their careers. At Great Learning, our focus is on creating industry relevant programs and crafting learning experiences that help candidates learn, apply and demonstrate capabilities in areas that are driving the future.
We are on a mission to make professionals proficient and future ready. In the last 5 years, we have been able to deliver 5+ million hours of learning to professionals worldwide with thousands of them being able to achieve a successful career progression in leading companies such as Microsoft, Amazon, Adobe, American Express, Deloitte, IBM, Accenture, McKinsey and more.

